[CVPR2021] CVPR2021-3D Vision 논문 훑기 (3)
CVPR(IEEE Conference on Computer Vision and Pattern Recognition)은 컴퓨터 비전과 패턴 인식 분야에서 세계적으로 최고 수준의(Top-tier) 학회이다. 이번 포스팅에서는 2021년도 CVPR 학회에서 3D Vision 주제에 관한 몇 가지 논문들을 Abstract 위주로 살펴본다.
관심 논문
내가 관심있는 주제에 관련된 몇 가지 논문을 abstract 위주로 살펴본다.
3D(3차원 비전)
- A Deep Emulator for Secondary Motion of 3D Characters
- Neural Deformation Graphs for Globally-consistent Non-rigid Reconstruction
- Deep Implicit Templates for 3D Shape Representation
- SMPLicit: Topology-aware Generative Model for Clothed People
- Picasso: A CUDA-based Library for Deep Learning over 3D Meshes
- Semi-supervised Synthesis of High-Resolution Editable Textures for 3D Humans
- RGB-D Local Implicit Function for Depth Completion of Transparent Objects
- Deep Two-View Structure-from-Motion Revisited
- Deformed Implicit Field: Modeling 3D Shapes with Learned Dense Correspondence
- S3: Neural Shape, Skeleton, and Skinning Fields for 3D Human Modeling
- Plan2Scene: Converting Floorplans to 3D Scenes
- Shelf-Supervised Mesh Prediction in the Wild
- Unsupervised Learning of 3D Object Categories from Videos in the Wild
A Deep Emulator for Secondary Motion of 3D Characters
Mianlun Zheng, Yi Zhou, Duygu Ceylan, Jernej Barbič (link)

배경
- 3차원 캐릭터를 애니메이션화하기 위한 빠르고 가벼운 방법은 컴퓨터 게임과 같은 다양한 애플리케이션에 적합하다.
해결
-
생생한 2차 모션 효과로 3D 캐릭터의 skinning 기반 애니메이션을 향상시키는 학습 기반 접근 방식을 제안한다.
-
인접 정점(vertices) 사이의 내부 힘을 암시적으로 인코딩하는 캐릭터 시뮬레이션 메쉬의 각 로컬 패치를 인코딩하는 신경망을 설계하였다.
이 네트워크는 캐릭터 역학의 상미분 방정식(ordinary differential equations)을 emulate하여, 현재의 가속도, 속도, 그리고 위치로부터 새로운 정점(vertex)의 위치를 예측한다.
로컬 방식이므로, 이러한 네트워크는 mesh topology에 독립적이며, 테스트시 임의의 모양을 갖는 3D character meshes로 일반화된다.
-
정점(vertex)당 제약 조건과 강성(stiffness)과 같은 재료 속성을 통해, mesh의 서로 다른 부분에서 역학을 쉽게 조정할 수 있다.
결론
- 이러한 방식을 다양한 캐릭터 메쉬와 복잡한 모션 시퀀스에 대해 평가하였다.
- 실제(ground-truth) 물리적 기반 시뮬레이션에 비해 30배 더 효율적일 수 있으며, 빠른 근사치를 제공하는 대체 솔루션보다 성능이 뛰어남을 보였다.
컴퓨터 게임과 같은 애플리케이션에서는 빠르고 가벼운 3D 캐릭터 애니메이션 기법이 요구된다. 이에, 캐릭터 역학의 상미분 방정식을 에뮬레이트하여, 현재의 가속도, 속도, 그리고 위치 정보로부터 새로운 정점의 위치를 예측하는 로컬 방식의 네트워크를 제안한다. 이를 통해 정점당 제약 조건과 강성과 같은 재료 속성을 통해 역학을 쉽게 조정할 수 있다.
Neural Deformation Graphs for Globally-consistent Non-rigid Reconstruction
Aljaž Božič, Pablo Palafox, Michael Zollhöfer, Justus Thies, Angela Dai, Matthias Nießner (link)

배경
- 단단하지 않은 변형 표면을 캡처하는 것은 종종 매우 역동적인 실제 환경을 재구성하고 이해하는 데 필수적이다.
- 정적 3D 씬(scene) 재구성에 인상적인 발전이 이루어졌지만, 동적 추적 및 재구성은 여전히 매우 어려운 과제이다.
해결
-
전역적으로 일관된(globally-consistent) 변형 추적(deformation tracking) 및 비강체(non-rigid) 객체의 3D 재구성을 위한 Neural Deformation Graphs를 제안한다.
특히 심층 신경망(deep neural network)을 통해 변형 그래프를 암시적으로 모델링한다.
-
신경 변형 그래프(neural deformation graph)는 어떤 객체의 특정 구조에 의존하지 않으므로, 일반 비강성 변형 추정에 적용할 수 있다.
움직이지 않는 물체(non-rigidly moving)의 주어진 깊이 카메라 관찰 시퀀스에서 이러한 신경 그래프를 전역적으로 최적화한다.
명시적 관점에서의 일관성과 프레임간 그래프 및 표면 일관성 제약을 기반으로, 기본 네트워크가 자체 감독(self-supervised) 방식으로 학습된다.
-
암시적으로 변형 가능한 다중 MLP 모양 표현을 사용하여, 객체의 기하학에 대해 추가로 최적화한다.
결론
- 순차적 입력 데이터를 가정하지 않으므로, 빠른 동작 또는 일시적으로 연결이 끊긴 녹음에 대해 강력한 추적을 가능하게 해준다.
- 실험을 통해, Neural Deformation Graphs가 64% 개선된 재구성과, 62% 개선된 변형 추적 성능임을 증명했다. 이는, 질적 및 양적으로 최첨단 비강체 재구성 접근 방식을 능가함을 보여주는 결과이다.
단단하지 않은 변형 표면을 캡처하는 것은 역동적인 실제 환경을 재구성하는 데에 필수적이지만, 여전히 어려운 과제이다. Neural Deformation Graphs는 명시적 관점에서 일관성과 프레임간 그래프 및 표면 일관성 제약을 기반으로 self-supervised 방식으로 학습되는 기본 네트워크를 포함한다. 순차적인 입력 데이터를 가정하지 않으므로 빠른 동작을 가능하게 한다.
Deep Implicit Templates for 3D Shape Representation
Zerong Zheng, Tao Yu, Qionghai Dai, Yebin Liu (link)

배경
-
일종의 3D 모양 표현인 Deep implicit functions (DIFs)은 컴팩트함과 강력한 표현력덕분에 3D vision 커뮤니티에서 점점 더 대중화되고 있다.
그러나 폴리곤 메쉬 기반 템플릿(polygon mesh-based templates)과 달리, DIF로 표현되는 모양 전반에 걸쳐 dense correspondences 혹은 다른 의미론적 관계(semantic relationships)를 추론하는 것은 여전히 도전 과제로 남아있으며, 이는 텍스처 전송, 모양 분석 등에 적용하는 것을 제한한다.
해결
-
이러한 한계를 극복하고 DIF를 더 해석하기 쉽게 만들기 위해, deep implicit representations에서 명시적 대응 추론을 지원하는 Deep Implicit Templates라는 새로운 3D 모양 표현 방법을 제안한다.
-
핵심 아이디어는, DIF를 template implicit function의 조건부 변형(conditional deformations)으로 공식화하는 것이다.
이를 위해, 조건부 공간 변환(conditional spatial transformation)을 다중 아핀 변환(multiple affine transformations)으로 분해하고, 일반화 능력을 보장하는 공간 왜곡 LSTM(Spatial Warping LSTM)을 제안한다.
-
training loss는 unsupervised 방식에서 정확한 대응과 그럴듯한 템플릿을 학습하면서, 높은 재구성 정확도를 달성하기 위해 신중하게 설계되었다.
결론
- 실험을 통해, 이러한 방식이 모양 컬렉션에 대한 공통적인 implicit template을 학습할 수 있을 뿐만 아니라, 어떠한 supervision 없이도 모든 모양에 대해 동시에 조밀한 대응을 설정할 수 있음을 밝혔다.
3D vision 분야에서 Deep implicit funtions는 컴팩트함과 강력한 표현력으로 인해 대중화되고있다. 하지만 DIF로 표현되는 모양 전반에 걸쳐 조밀한 대응(dense correspondences)과 의미론적 관계를 추론하는 것은 여전히 도전 과제이다. 이러한 한계를 극복하고자 DIF를 조건부 변형으로 공식화하는 Deep Implicit Templates라는 새로운 3D 모양 표현 방법을 제안하여 이러한 문제를 해결하였다.
SMPLicit: Topology-aware Generative Model for Clothed People
Enric Corona, Albert Pumarola, Guillem Alenyà, Gerard Pons-Moll, Francesc Moreno-Noguer (link)
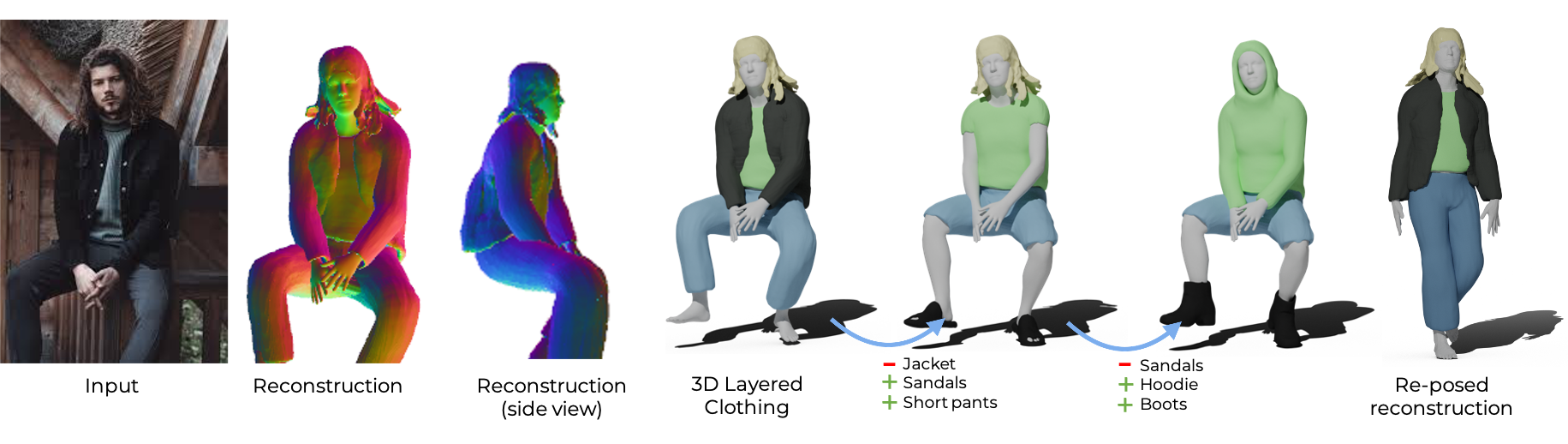
배경
- 다양한 신체 형태와 포즈로 의복 스타일과 변형을 제어할 수 있는 차별화된 저차원 생성 모델 구축을 통해, 옷을 입은 사람의 디지털 애니메이션, 3D 콘텐츠 제작 및 가상 시승과 같은 여러 가지 흥미로운 애플리케이션에 문을 열 수 있다.
해결: SMPLicit
-
신체 포즈, 모양, 그리고 옷의 기하학을 공동으로 표현하는 신박한 생성 모델인 SMPLicit을 제안한다.
-
각 유형의 의류에 대해 특정 모델을 학습해야하는 기존의 학습 기반 방식과 달리, SMPLicit은 의류의 사이즈나 타이트함/루즈함과 같은 다른 특성들을 제어하면서 다양한 의류 topologies(e.g., 민소매옷부터 후드티, 오픈 재킷까지)를 통일된 방식으로 표현할 수 있다.
-
이러한 모델을 티셔츠, 후드티, 재킷, 반바지, 바지, 스커트, 신발, 심지어 헤어를 포함한 다양한 의복에 적용할 수 있음을 보였다.
-
SMPLicit의 표현 유연성(flexibility)은 SMPL 인체 매개변수와 의미론적으로 해석가능하며 의류 속성으로 정렬된 학습 가능한 잠재 공간으로 조건화된 암시적 모델(implicit model)을 기반으로 한다.
제안된 모델은 완전히 미분가능하므로, 더 큰 end-to-end 학습 가능한 시스템에 적용할 수 있다.
결론
-
실험을 통해, SMPLicit이 3D 스캔을 피팅하고, 옷 입음 사람의 이미지에서 3D 재구성에 쉽게 사용할 수 있음을 보여준다.
두 경우 모두, 복답한 의복의 형상을 검색하고, 여러 겹의 의복이 있는 상황을 처리하고, 손쉬운 의상 편집을 위한 도구를 제공함으로써 최첨단 기술을 뛰어넘을 수 있다.
-
이러한 방향의 추가 연구를 위해서, [여기](http://www.iri.upc.edu/people/ecorona/smplicit/에 있는 코드와 모델을 공개적으로 사용할 수 있다.
신체 포즈, 모양, 그리고 옷의 기하학을 표현하는 신박한 생성 모델인 SMPLicit을 통해 다양한 애플리케이션에 문을 열 수 있을 것이라 기대된다. 기존에는 각 유형의 의류에 대해 특정 모델을 학습해야했지만, SMPLicit은 다양한 의류 topologies를 통일된 방식으로 표현할 수 있다.
Picasso: A CUDA-based Library for Deep Learning over 3D Meshes
Huan Lei, Naveed Akhtar, Ajmal Mian (link)
배경
-
계층 신경 아키텍처(Hierarchical neural architectures)는 빠른 mesh decimation의 필요성을 나타내는 다중 스케일 추출에서 효과적이라 입증되었다.
그러나 기존의 방법은 다중 해상도 메쉬를 얻기 위해 CPU 기반 구현에 의존한다.
해결: Picasso
-
복잡한 실제 3D 메쉬에 대한 딥러닝을 위한 새로운 모듈로 구성된 CUDA 기반 라이브러리인 Picasso를 소개한다. 이처럼 GPU 가속 mesh decimation을 설계하여, 네트워크 해상도 감소를 효율적으로 즉각 촉진할 수 있다.
-
Pooling 및 unpooling 모듈은 decimation 동안 수집된 정점 클러스터(vertex clusters)로 정의된다.
-
Picasso는, 메쉬에 대한 특징 학습에 대해, 소위 facet2vertex, vertex2facet, 그리고 facet2facet convolution이라 불리는 세 가지 유형의 새로운 컨볼루션을 포함한다.
따라서 mesh를 기존의 방식처럼 모서리(edges)가 있는 공간 그래프가 아니라 꼭짓점(vertices)과 면(facets)으로 구성된 기하학적 구조로 취급한다.
-
Picasso는 메쉬 샘플링 (정점 밀도)에 대한 robustness를 위해 필터에 fuzzy mechanism을 통합한다.
Gaussian mixtures를 활용하여 facet2vertex convolution에 대한 fuzzy 계수를 정의하고, 무게 중심 보간(varycentric interpolation)을 활용하여 나머지 두 컨볼루션에 대한 계수를 정의한다.
결론
- 이 release에서는, S3DIS에 대한 경쟁력있는 세분화 결과와 함께 제안된 모듈의 효율성을 보여주었다.
- 해당 라이브러리는 여기에서 공개하였다.
계층 신경 아키텍처는 다중 스케일 추출에서 효과적이라 입증되었다. 하지만 기존의 방법은 CPU 기반으로 구현되었다. 이에, 복잡한 실제 3D mesh에 대한 딥러닝을 위한 새로운 모듈로 구성된 Picasso라는 CUDA GPU기반 라이브러리를 제안하였다.
Semi-supervised Synthesis of High-Resolution Editable Textures for 3D Humans
Bindita Chaudhuri, Nikolaos Sarafianos, Linda Shapiro, Tony Tung (link)

배경
- 최근 AR/VR 기기 및 가상 커뮤니케이션의 사용이 증가함에 따라 3D Human Avatar 제작이 인기를 얻고 있다.
- 인체는 모양을 모델링한 3D 표면 메시와 3D 표면에 매핑된 모양을 인코딩한 텍스처 맵(UV 공간의 이미지)으로 표현되며, 이때 몰입적인 경험을 위해서는 아바타의 사실적인 질감이 매우 중요하다.
해결
-
semi-supervised 설정에서 3D human meshes에 대한 다양한 고충실도(high fidelity) 텍스처 맵을 생성하는 새로운 접근 방식이다.
-
텍스처맵에서 의미 영역(semantic regions)의 레이아웃을 정의하는 분할 마스크(segmentation mask)가 주어졌을 때, 제안된 네트워크는 렌더링을 목적으로 사용되는 다양한 스타일을 갖는 고해상도 텍스처를 생성한다.
이를 달성하기 위해, 각 영역의 스타일 확률 분포를 개별적으로 학습하여 지역별 분포로부터 샘플링하여 생성된 텍스처의 스타일을 제어할 수 있는 Region-adaptive Adverserial Variational AutoEncoder(ReAVAE)를 제안한다.
-
또한, single-view RGB 입력으로부터 가져온 데이터로 학습 세트를 보강(augment)할 수 있는 데이터 생성 기술을 제안한다.
이러한 학습 전략은 참조 이미지 스타일을 다양한 영역에 대한 임의의 스타일과 혼합할 수 있도록 하며, 이는 가상 체험 AR/VR 어플리케이션에 유용한 속성이다.
결론
- 실험을 통해, 이러한 방식이 이전의 작업과 비교했을 때 더 나은 텍스처맵을 합성함과 동시에 독립적인 레이아웃과 스타일 제어 능력을 가능하게함을 보였다.
레이아웃을 정의하는 분할 마스크가 주어졌을 때, 다양한 스타일을 갖는 고해상도 텍스처를 생성하는 접근 방식을 제안한다. 각 스타일 확률 분포를 개별적으로 학습하여, 생성된 텍스처의 스타일을 제어할 수 있는 Region-adaptive Adverserial Variational AutoEncoder(ReAVAE)를 통해 달성할 수 있다. 또한 signle-view RGB 입력으로부터 학습 세트를 보강할 수 있는 데이터 생성 기술을 제안한다. 이를 통해 더 나은 텍스처맵을 합성할 수 있으며, 독립적인 레이아웃과 스타일 제어 능력을 보여주었다.
RGB-D Local Implicit Function for Depth Completion of Transparent Objects
Luyang Zhu, Arsalan Mousavian, Yu Xiang, Hammad Mazhar, Jozef van Eenbergen, Shoubhik Debnath, Dieter Fox (link)

배경
- 로봇공학에서 대부분의 인지(perception) 방법은 RGB-D 카메라에 의한 깊이 정보를 필요로 한다. 그러나, 표준 3D 센서는 빛의 굴절(refraction)와 흡수(absorption) 문제로 인해 투명한 물체에 대한 깊이 정보를 취득하지 못한다.
해결
-
접근 방식의 핵심은 제안된 방식이 보이지 않는 물체를 일반화하고 빠른 추론 속도를 달성하도록 하는 ray-voxel pairs 기반 local implicit neural representation이다. 이러한 표현법에 기반하여, 노이지한 RGB-D 입력이 주어졌을 때, 누락된 깊이 정보를 완성할 수 있는 신박한 프레임워크를 제안한다.
또한, self-correcting refinement model을 사용하여 반복적으로 깊이 추정을 더욱 개선할 수 있다.
-
전체 파이프라인을 학습하기 위해, 투명한 객체를 갖는 대규모 합성 데이터 세트를 구축하였다.
결론
- 실험을 통해, 이러한 방법이 합성 데이터와 실제 데이터 모두에서 최신 최첨단 기법을 능가하는 성능을 보임을 밝혔다. 또한, 이전의 가장 뛰어난 방법인 ClearGrasp와 비교했을 때 추론 속도를 20배 향상시킴을 보였다.
- 코드와 데이터세트는 여기에서 확인할 수 있다.
로봇 공학에서 대부분의 인지 기법은 깊이 정보를 필요로하지만, RGB-D 카메라의 한계로 인해 투명한 물체에 대한 깊이 정보는 취득하지 못한다. 이에 ray-voxel pairs 기반 local implicit neural representation을 통해 누락된 깊이 정보를 완성할 수 있는 프레임워크를 제안한다. 실험을 통해 해당 방법이 합성 데이터와 실제 데이터 모두에서 뛰어남을 증명하였다.
Deep Two-View Structure-from-Motion Revisited
Jianyuan Wang, Yiran Zhong, Yuchao Dai, Stan Birchfield, Kaihao Zhang, Nikolai Smolyanskiy, Hongdong Li (link)

배경
- Two-view structure-from-motion(SfM)은 3D 재구성 및 시각적 SLAM의 초석이다.
- 기존의 딥러닝 기반 방식은 이러한 문제를 두 개의 연속 프레임으로 부터 절대적인 포즈 스케일을 복구하거나, 단일 이미지로부터 깊이 맵을 예측하는 방식으로 해결했다. 하지만 두 방법 모두 잘못된 문제이다.
해결
- 고전적인 파이프라인의 좋은 자세(well-posedness)를 활용하여 깊은 두 시점 SfM의 문제를 재검토할 것을 제안한다.
- 제안된 방법은 다음으로 구성된다.
- 두 프레임 사이의 조밀한 대응을 예측하는 광류(optical flow) 추정 네트워크
- 2D 광류 대응으로부터 상대적인 카메라 포즈를 계산하는 정규화된 포즈 추정 모듈
- 탐색 공간을 줄이고, 조밀한 대응을 정제하고, 상대적인 깊이맵을 추정하기위해 에피폴라 기하학(epipolar geometry)을 활용하는 스케일 불변 깊이 추정 네트워크
결론
- 광범위한 실험을 통해, 제안된 방법이 상대적 포즈와 깊이 추정 모두에 대해 KITTI depth, KITTI VO, MVS, Scenes11, 그리고 SUN3D 데이터세트에 대한 명확한 마진으로 모든 최첨단 두 시점 SfM 방법을 능가함을 보였다.
SfM은 3D 재구성과 visual SLAM의 초석이다.그러나 기존의 딥러닝 기반 방법은 SfM 문제를 잘못해결했으며, 이에 고전적인 파이프라인 well-posedness를 활용하여 SfM 문제를 재검토할 것을 제안한다. 실험을 통해 상대적 포즈와 깊이 추정 모두에서 최첨단 방법을 능가했음을 보였다.
Deformed Implicit Field: Modeling 3D Shapes with Learned Dense Correspondence
Yu Deng, Jiaolong Yang, Xin Tong (link)

배경
- 동일한 클래스의 3D 객체는 몇 가지 공통 모양 특징과 의미적 대응성을 공유한다. 따라서 형상 이해(shape understanding), 재구성(reconstruction), 조작(manipulation), 이미지 합성(image synthesis)과 같은 3D 및 2D 영역에서 다양한 다운스트림 작업에 유용한 변형 형상 모델(deformable shape model)을 구축하는 데 사용될 수 있다.
해결: Deformed Implicit Field(DIF)
- 카테고리의 3D 모양을 모델링하고 모양간의 dense correspondences를 생성하기 위한 새로운 Deformed Implicit Field(DIF) 표현법을 제안한다.
- DIF를 이용하여, 3D 모양을 각 모양 인스턴스에 대한 3D 변형 필드 및 수정 필드와 함께 카테고리 전체에서 공유되는 template implicit field로 표현할 수 있다. 모양 일치는 변형 필드를 사용하여 쉽게 설정할 수 있다.
- DIF-Net이라 불리는 제안된 신경망은, 어떠한 대응이나 부분 라벨도 없이 카테고리에 속한 3D 객체에 대한 모양 잠재 공간과 이러한 필드를 공동으로 학습한다. 학습된 DIF-Net은 또한 모양 구조 불일치를 반영하는 신뢰할 수 있는 대응 불확실성 측정을 제공할 수 있다.
결론
- 실험을 통해, DIF-Net이 충실도가 높은 3D 모양을 생성할 뿐만 아니라 다양한 모양에 걸쳐 고품질의 조밀한 대응 관계를 구축함을 보였다.
- 이러한 방법이 이전 방법으로는 달성할 수 없었던 텍스처 전송(texture transfer) 및 모양 편집(shape editing)과 같은 여러 응용 프로그램을 시연함을 보였다.
동일한 클래스의 3D 객체는 변형 형상 모델(deformable shape model)을 구축하는 데에 사용될 수 있다. 카테고리에서 3D 모양을 모델링하고 모양간 dense correspondences를 생성하기 위한 새로운 Deformed Implicit Field(DIF) 표현법을 통해, 카테고리 전체에서 공유되는 3D 모양을 생성할 뿐만 아니라 다양한 모양에 걸쳐 고품질의 dense correspondences를 구축할 수 있다.
S3: Neural Shape, Skeleton, and Skinning Fields for 3D Human Modeling
Ze Yang, Shenlong Wang, Sivabalan Manivasagam, Zeng Huang, Wei-Chiu Ma, Xinchen Yan, Ersin Yumer, Raquel Urtasun (link)

배경
- 인간을 구성하고 애니메이션에 적용하는 것은 VR 혹은 시뮬레이션에서 로봇공학 테스트와 같이 다양한 응용 분야에서 가상 세계를 구축하는 데에 중요한 구성 요소이다. 다양한 모양, 자세, 그리고 옷을 가진 인간의 변형이 기하급수적으로 많으므로, 실제 데이터로부터 대규모로 인간을 자동으로 재구성하고 애니메이션할 수 있는 방법을 개발하는 것은 중요하다.
해결
-
보행자의 모양, 자세, 그리고 스키닝 가중치(skinning weights)를 데이터로부터 직접적으로 학습된 neural implicit functions로 표현하는 방법을 제안한다.
이러한 표현 방법은 human paremetric body model에 명시적으로 맞추지(fit) 않으면서 다양한 보행자의 모양과 자세를 처리할 수 있으므로, 더 넓은 범위의 인간 기하학과 토폴로지를 처리할 수 있다.
결론
- 다양한 데이터 세트에 대해 이러한 접근 방식이 효율적임을 보였다.
- 이러한 재구성이 기존의 최첨단 방법을 능가함을 보였다.
- 재애니메이션(re-animation) 실험을 통해, 단일 RGB 이미지 (및/또는 선택적인 LiDAR sweep)을 입력으로부터 3D 인간 애니메이션을 대규모로 생성할 수 있음을 보였다.
단일 RGB 이미지 (및/또는 optional LiDAR sweep) 입력으로 부터 보행자의 모양, 자세, 그리고 skinning weights을 직접적으로 학습하여 neural implicit function으로 표현하는 방법을 제안하였다.
Plan2Scene: Converting Floorplans to 3D Scenes
Madhawa Vidanapathirana, Qirui Wu, Yasutaka Furukawa, Angel X. Chang, Manolis Savva (link, project)

해결: Plan2Scene
- Plan2Scene은 평면도와 주택 관련 사진 세트를 질감이 있는 3D mesh 모델로 변환하는 작업이다.
- 제안된 시스템은 1) 평면도 이미지를 3D mesh 모델로 들어올리며(lift), 2) 입력 사진을 기반으로 표면 질감을 합성하고, 3) 그래프 신경망 아키텍처를 사용하여 관찰되지 않은 표면에 대한 텍스처를 추론한다.
- 시스템을 훈련하고 평가하기 위해 실내 표면 텍스처 데이터 세트를 만들고, 수정된 표면 작물(surface crops) 및 추가적인 주석을 통해 이전 작업의 평면도 및 사진 데이터 세트를 보강(augment)한다.
결론
- 제안된 접근 방식은 거주지를 일부가 덮인 정렬되지 않은 드문드문한 사진 세트로부터 바닥, 벽, 그리고 천장과 같은 지배적인 표면에 대해 타일링 가능한 텍스처를 생성하는 문제를 처리한다.
- 정성적·정량적 평가를 통해, 이러한 시스템이 사실적인 3D 인테리어 모델을 생성하고, 텍스처 품질 메트릭 세트에 대한 baseline 접근 방식을 능가함을 보였다.
평면도 사진과 거주지의 일부 사진세트로부터 바닥, 벽, 그리고 천장과 같은 타일링 가능한 텍스처를 생성하는 시스템을 제안한다. 이를 통해 사실적인 3D 인테리어 모델을 생성할 수 있으며, 텍스처 품질 메트릭 세트에 대한 baseline 접근 방식을 능가할 수 있다.
Shelf-Supervised Mesh Prediction in the Wild
Yufei Ye, Shubham Tulsiani, Abhinav Gupta (link, project)

배경
- 대부분의 야생에서의 컴퓨터 비전 시스템은 여전히 2D 의미 인식(분류/탐지)(2D semantic recognition)을 수행한다.
- 최근 2D 인식의 발전은 지도 학습(supervised learning)에서 비롯되었지만, 2D semantic tasks와 달리 3D understanding에 대해 감독(supervision)을 받는 것은 여전히 확장 가능하지 않다.
- 최근 2D 접근방식의 감독을 갖는 3D 접근 방식을 구축하려는 시도가 있었으나, 초기 접근법은 다중 뷰 감독을 사용하는 것에 초점을 맞추었다. 그러나 동일한 개체/장면에 대한 다중 뷰를 얻는 것은 쉽지 않다는 문제가 있다.
해결
-
단일 이미지로부터 객체의 3D 모양과 자세을 추론하는 것을 돕고, off-the-shelf 인식 시스템(i.e. ‘shelf-supervised’)의 분할 출력만으로 감독되는 구조화되지 않은 이미지 컬렉션으로부터 학습할 수 있는 학습기반 접근방식을 제안한다.
-
먼저, 카메라 포즈와 함께 표준 프레임에서 체적 표현(volumetric representation)을 추론한다. 모양과 마스크 모두와 기하학적으로 일치하는 표현을 시행하고, 합성된 새로운 뷰가 이미지 컬렉션과 구별되지 않도록 한다. 거친 체적 예측(the coarse volumetric predictions)은 메쉬 기반 표현으로 변환되어, 예측된 카메라 프레임에서 더욱 세분화된다.
이러한 두 단계를 통해 이미지 컬렉션의 모양-포즈 인수분해와 인스턴스별 재구성을 보다 세부적으로 수행할 수 있다.
결론
- 합성 데이터 세트와 실제 데이터 세트 모두에서 방법을 조사하고, 기존 작업보다 훨씬 더 많은 클래스인 야생에서의 50가지 범주에서 확장성을 보였다.
기존의 2D 접근 방식의 감독을 갖는 3D 접근 방식은 다중 뷰 감독을 사용하는 것에 초점을 맞추었지만, 동일한 개체/장면에 대해 다중 뷰를 갖는 것은 쉽지 않다. 단일 이미지로부터 3D 모양과 자세를 추론하는 것을 돕고, off-the-shelf 인식 시스템의 분할 출력만으로 감독되는 학습 기반 3D 접근 방식을 통해 이러한 문제에 접근할 수 있다. 실험 결과, 기존 작업보다 훨씬 더 많은 클래스에 대해 확장성을 보였다.
Unsupervised Learning of 3D Object Categories from Videos in the Wild
Philipp Henzler, Jeremy Reizenstein, Patrick Labatut, Roman Shapovalov, Tobias Ritschel, Andrea Vedaldi, David Novotny (link)

배경
- 최근 합성 데이터를 사용하거나 키포인트와 같은 2D 기본 요소가 사용가능하다고 가정하여 유사한 결과를 얻었다.
해결
- 논문은 수동적인 주석 없이 도전적인 실제 데이터로 학습하는 방식에 주목했다. 따라서 대규모 객체 인스턴스 컬렉션의 다중 뷰로부터 모델을 학습하는 것에 중점을 두었다.
- 주어진 카테고리의 객체에 대한 적은 수의 이미지가 주어졌을 때, 그것을 3D로 재구성하는 심층 네트워크를 학습하는 것을 목표로 한다.
- 모델들의 이러한 클래스를 훈련하고 벤치마킹하는 데에 적합한 객체 중심 비디오의 새로운 대규모 데이터 세트를 제공한다.
- 마지막으로 WCR(warp-conditional ray embedding)이라는 새로운 신경망 설계를 제안한다. WCR은 객체의 표면과 질감의 상세한 implicit representation을 얻는 동안 재구성을 크게 개선하고, 학습 프로세스를 부트스트랩(bootstrap)한 초기 SfM 재구성 노이즈를 보상한다.
결론
- 격리된 객체를 재구성하는 데에 잘 작동하는 메쉬, 복셀, 또는 암시적인 표면(implicit surfaces)을 활용하는 기존의 기술은 제안된 대규모 데이터 세트에 적합하지 않다.
- 기존 벤치마크와 새로운 데이터 세트에 대한 여러 심층 단안 재구성 기준선(deep monocular reconstruction baselines)에 대한 성능 향상을 보였다.
최근의 3D reconstruction 문제는 합성 데이터를 사용하거나, 키포인트와 같은 2D 기본 요소가 사용가능하다 가정하여 문제를 해결하였다. 본 논문은 대규모 객체 인스턴스 컬렉션의 다중 뷰가 주어졌을 때, 수동적인 주석 없이 실제 데이터로 학습하는 도전적인 방법에 주목하였다. 주어진 카테고리에 대해 적은 수의 이미지가 주어졌을 때 이를 3D로 재구성하는 심층 네트워크로 학습하여 이를 달성한다.
References
- CVPR 2021: http://cvpr2021.thecvf.com/
- brunch/kakao-it: https://brunch.co.kr/@kakao-it/297
- CVPR-2021-Paper-Satistics : https://github.com/hoya012/CVPR-2021-Paper-Statistics?fbclid=IwAR0MGG3x-9bDU8YjVp-UGHcJDAXUspNwJ3Iy-o17oi7UFbTSFGcKS_OqbaQ
- 52CV/CVPR-2021-Papers: https://github.com/52CV/CVPR-2021-Papers
- amusi/CVPR2021-Papers-with-Code: https://github.com/amusi/CVPR2021-Papers-with-Code